読みづらい「全文公開」はもったいない
書籍の「全文公開」って良いですよね。
マーケティング界のスゴい発明だと思います。
「全文公開」のおかげで私たちは、書籍を購入するまでのハードルを超えて、気になっていた著者や作品への興味を深めることができるわけです。
ただ、全ての「全文公開」記事が、Webの読者に適した形にマークアップされているわけではありません。
一部の記事は、"書籍の画像"を貼り付ける形で「全文公開」がされています。
当然ですが、画像で構成された「全文公開」記事が、読者の閲覧端末に合わせて最適化されることはありません。
また、これは個人的な意見ですが、画面をスクロールしながら画像の連続を読む、という読書体験はあまり心地の良いものではないと思います。
そこで私は、そんな画像でできた「全文公開」記事をPDFにして、電子書籍のように読むことにしました。

PDF化したことで、私の読書へのモチベーションは明らかに上がりました。
読書において、読みやすさって大前提なんだなと実感させられました。
今回はそんなTipsを共有すべく、PDFを作るまでの一連の流れを紹介します。
画像ベタ貼りの「全文公開」記事をPDFにする
PDFを作るまでの工程は、次の通りです。
それぞれ、詳しく解説します。
1. 記事内の画像をすべてDL
まずはPDFの素材となる画像データを収集します。
一つ一つ手作業でDLするのは面倒なので、今回はImage Downloaderを使います。
Image Downloaderは、表示するWebページから画像を一括でDLするためのChrome拡張です。
画像のナンバリングもできて、とても便利なツールです。
今回は例として、カジュアルに人物スケッチを学べることで人気の下田スケッチ人物本の「全文公開」記事を使って説明します。
Image Downloaderをインストール後、対象の記事を表示したら、次のように画像をDLしましょう。
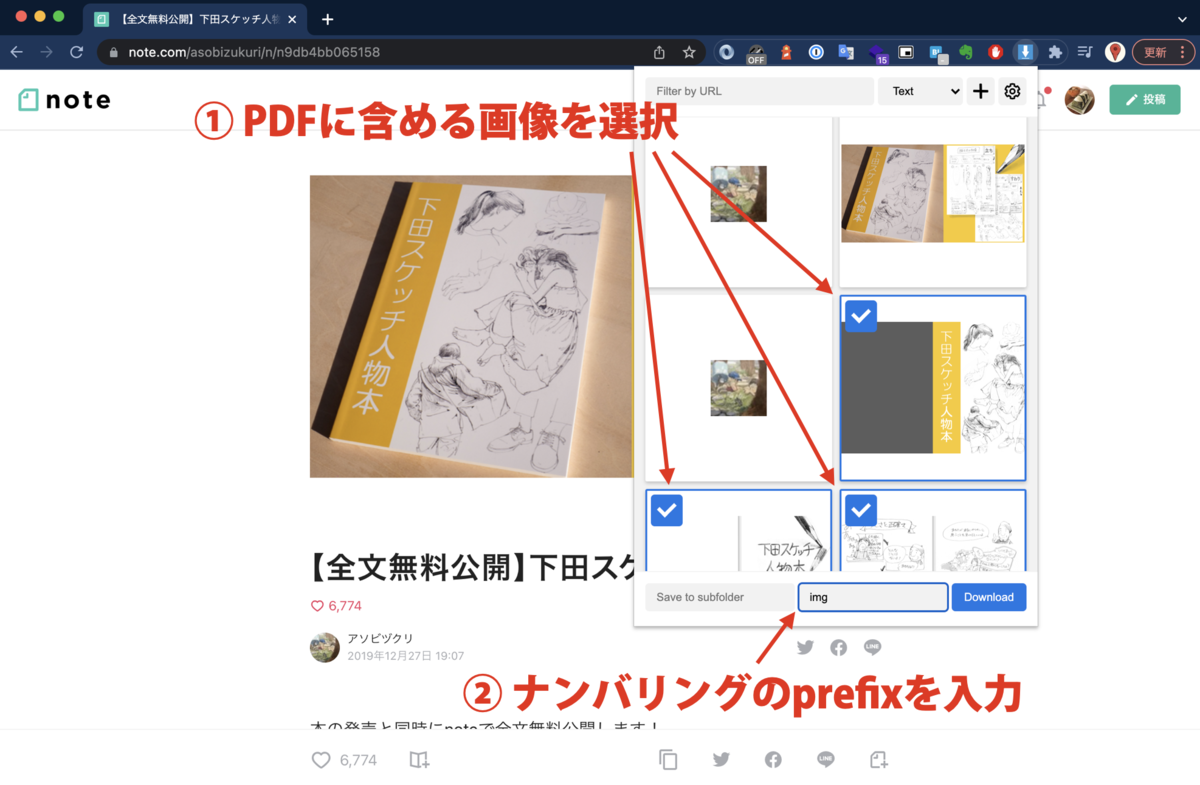
① PDFに含める画像を選択
(「Select all」にチェックマークを付けて不要な画像を除くと楽)
② ナンバリングのprefixを入力
(この例だと、”img01”, “img02” ... という名前で画像がDLされる)
ちなみにnoteの記事は、画像にLazyloadが設定してあるので、事前に一番下までスクロールして全ての画像を読み込んでおきましょう。
DL後は、一つのフォルダに画像をまとめておいてください。
2. 画像をPythonスクリプトで読み込み、PDFを作成
DLした画像から、1つのPDFを作ります。
色々と方法はありますが、今回は次のPythonスクリプトを使います。
from PIL import Image import os if __name__ == '__main__': # Function to sort by modified dates def getfiles(dirpath): a = [s for s in os.listdir(dirpath) if os.path.isfile(os.path.join(dirpath, s))] a.sort(key=lambda s: os.path.getmtime(os.path.join(dirpath, s))) return a # Declare an empty list img_list = [] # Request user input for pdf filename and image folder path folder = input("Enter the path of images folder : ") pdf_filename = folder.split("\\")[-1] + ".pdf" files = getfiles(folder) # get the files sorted by modified dates files.sort() print('Processing....') for count, filename in enumerate(files): image = Image.open(folder+'/'+filename) #open each file image = image.convert('RGB') # To change as portrait layout for landscape images width, height = image.size if(width>height): image = image.transpose(Image.ROTATE_90) # Append each processed image in img_list[] img_list.append(image) # All images in img_list[] are converted to a pdf img_list[0].save(pdf_filename, "PDF", resolution=100.0, save_all=True, append_images=img_list[1:]) print("Done!")
ざっくりいうと、次のような内容のスクリプトです。
- input()で、画像をまとめたフォルダのパスを入力待ち
- 入力されたパスから、各画像のファイル名を取得
- 取得したファイル名をもとに、Pillowで各画像のレイアウトを統一
- PDFとして保存
実行例は次の通りです。
$ python img2pdf.py Enter the path of images folder : ./target/下田スケッチ人物本 Processing.... Done!
実行すると、画像を保存したフォルダと同じ名前のPDFが生成されます。
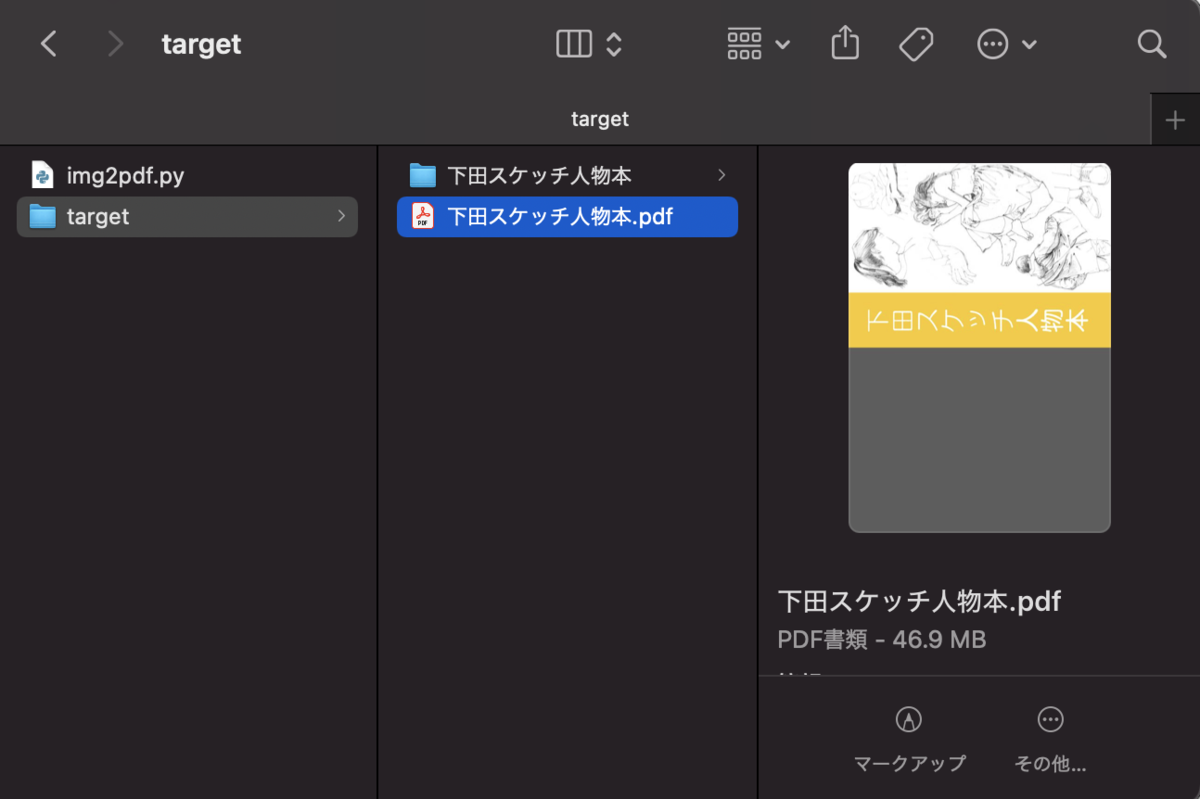
スマホなら縦長、タブレットだと横長のレイアウトにすると読みやすいと思います。
用途に合わせて、スクリプトを調整してみてください。
おわりに
今回は、画像でできた「全文公開」記事をPDFにして、電子書籍のように読むまでのプロセスを紹介しました。
これを参考に、みなさんの日常の読書がさらに捗るようになれば嬉しいです。
ただ、作ったPDFはあくまでも個人の目的で使うようにしてください。
画像の再配布を禁止している記事は多いです。用途については自己責任でお願いします。
参考リンク
(※この記事はWorks Human Intelligence Advent Calendar 2021に投稿しました)